Rank & Select for Systems Folks + our minor contribution to the area
Last Spring, I had the opportunity to teach a "special topics" course. I use that as shorthand for "Dave wants to learn about X, so I'll inflict my learning process upon some willing victims and collaborators called students." I roped in Michael Kaminsky to co-teach a course on "memory and resource efficient big data computing," which we pretty much defined as we went along. In fact, one of the first assignments for the students was to help come up with topics to discuss. CMU students are an awesome resource that way.
There's been a lot of exciting progress in memory-efficient data structures from the theory side of things in the last decade or so. Not all of it is usable yet, but some of it has that "this is almost there" feel to it that gets me salivating for the chance to refactor how I think about some aspects of system design. There are two themes that I think are particularly worth considering:

In the SEA paper, we also show how this structure works very nicely within a previous approach for select and simply makes it faster.
There's been a lot of exciting progress in memory-efficient data structures from the theory side of things in the last decade or so. Not all of it is usable yet, but some of it has that "this is almost there" feel to it that gets me salivating for the chance to refactor how I think about some aspects of system design. There are two themes that I think are particularly worth considering:
- The ideas behind succinct data structures
- Compressed indexes on compressed data
(I'll post a little more about #2 later, but hopefully, the idea of it is clear: Be able to search through compressed text (mostly), without ever having to un-gzip it.)
#1 is fun, and at the end of looking at the papers in this area, we decided that there was room for improvement by people who pay too much attention to CPU instructions and the memory hierarchy - namely, us. If it hasn't become clear from the stuff we've been working on lately, the algorithm engineering process is a ton of fun sometimes. :) This blog post is primarily about the context for and some of the work we published in our forthcoming SEA 2013 paper, led by Ph.D. student Dong Zhou, "Space-Efficient, High-Performance Rank & Select Structures on Uncompressed Bit Sequences".
What are Succinct Data Structures
The technical definition is "one that takes close to the information theoretic lower-bound for the structure." And if you're really being precise, if Z is that lower bound, a succinct structure takes Z + o(Z) size to represent. Remember that that little-oh means that it asymptotically takes only Z bits. But even those space-hogging "compact" data structures that take O(Z) bits are pretty fun to play with, despite possibly taking several times the information-theoretic lower bound.
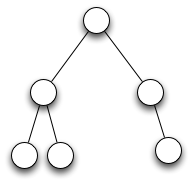
Succinct data structures came out of Guy Jacobson's Ph.D. thesis at Carnegie Mellon in 1989 and have received a lot of attention since then. One of the best examples is still his for a binary tree. Consider the tree on the left, and the conventional representation of it on the right:
 type Bintree struct {
type Bintree struct {
left *Bintree
right *Bintree
}
Bintree{ &Bintree{ &Bintree{}, &Bintree{} },
&Bintree{ left: nil, right: &Bintree{} }
}
Probably not an unfamiliar way to represent a binary tree.
How much space does that representation take? Two pointers (let's call them 64 bits, or 8 bytes) per node. With 6 nodes, that's a total of 96 bytes, or 768 bits. Here's a sneakier way of representing the same tree:
In binary: 111101000000
To decode that, for every "1" interpret it as meaning "there is a child", and for 0, meaning, "there is no child". Each node is represented by two bits. We represent them in "level order" - write down the nodes in the first level (the root), and then the nodes in the second level, and so on.
That representation takes 12 bits. Our previous one took 768 bits. Not bad, not bad.
But, you say, I can't navigate this tree!
Right you are. This is an implicit representation of the binary tree: It takes exactly Z bits to represent it, plus perhaps a few more to indicate the start or whatever other conventions you're using. But it's not random access. But we can make it so, with a little work. The implicit representation wasn't the genius of Jacobson's thesis: The navigation was.
If node 'n' is the i-th "real" node (not a blank spot):
So the key question is: Given a node in the tree, which real node is it? There might, after all, be gaps. The answer is: If we knew how many "1"s appeared before it in the bitwise representation, we know which real node it is.
This operation is called rank(x): Given a 0/1 bitvector, calculate how many 1s appear to the left of position x.
It has a corresponding function called select(y): Calculate the position at which the y-th 1 appears.
Thus, if you are currently at position p in the bitvector and you want to navigate to its left child, you would compute r = rank(p) and then go to position 2*r. (My notes from the course may also be helpful in distilling this.)
To go up the tree to the parent, you know that it is represented by the position/2-th real node in the tree. In other words, select(position/2).
Rank & select have a lot of other uses in creating succinct and compact datastructures, but that's one of the simplest. They tend to form one of the fundamental building blocks that are used by a lot of higher-level structures. (An even simpler one: Store a 50% sparse list of n objects in a single 100% dense array plus n bits.)
type Bintree struct {left *Bintree
right *Bintree
}
Bintree{ &Bintree{ &Bintree{}, &Bintree{} },
&Bintree{ left: nil, right: &Bintree{} }
}
Probably not an unfamiliar way to represent a binary tree.
How much space does that representation take? Two pointers (let's call them 64 bits, or 8 bytes) per node. With 6 nodes, that's a total of 96 bytes, or 768 bits. Here's a sneakier way of representing the same tree:
In binary: 111101000000
 |
| Level-order traversal of a binary tree |
That representation takes 12 bits. Our previous one took 768 bits. Not bad, not bad.
But, you say, I can't navigate this tree!
Right you are. This is an implicit representation of the binary tree: It takes exactly Z bits to represent it, plus perhaps a few more to indicate the start or whatever other conventions you're using. But it's not random access. But we can make it so, with a little work. The implicit representation wasn't the genius of Jacobson's thesis: The navigation was.
Rank & Select for Navigating Implicit Binary Trees
The basic observation is:If node 'n' is the i-th "real" node (not a blank spot):
- If it's left child's bit is at position x, it's right child's bit is at position x+1(Obvious: The bits are written sequentially)
- The left-child bit is stored at position 2*i
So the key question is: Given a node in the tree, which real node is it? There might, after all, be gaps. The answer is: If we knew how many "1"s appeared before it in the bitwise representation, we know which real node it is.
This operation is called rank(x): Given a 0/1 bitvector, calculate how many 1s appear to the left of position x.
It has a corresponding function called select(y): Calculate the position at which the y-th 1 appears.
Thus, if you are currently at position p in the bitvector and you want to navigate to its left child, you would compute r = rank(p) and then go to position 2*r. (My notes from the course may also be helpful in distilling this.)
To go up the tree to the parent, you know that it is represented by the position/2-th real node in the tree. In other words, select(position/2).
Rank & select have a lot of other uses in creating succinct and compact datastructures, but that's one of the simplest. They tend to form one of the fundamental building blocks that are used by a lot of higher-level structures. (An even simpler one: Store a 50% sparse list of n objects in a single 100% dense array plus n bits.)
A really naive implementation of rank & select
func rank(x int, b bitvector) (count int) {
for i := 0; i < x; i++ {
if b[i] == 1 {
count++
}
}
}
Of course, this takes O(N) time. So clearly, we need an index that lets us skip over most of the bitvector. But computing rank() as we showed it is pretty reasonable on, say, a 64 bit integer using a newer Intel CPU, if you'll forgive mixing the name of the gcc intrinsic and go syntax:
__builtin_popcount(x >> (64-pos))
Will count the number of 1s before position pos in the 64 bit integer x. It takes all of about two instructions. So one way to compute an index is:
1s_to_the_left_of uint64[ bits/64 ]
Of course, this doubles the space requirements, but it enables you to implement rank very quickly:
func rank(x int, b bitvector) int {
return 1s_to_the_left_of[x/64] +
popcount(bitvector[x/64] >> (64 - x%64))
}
Two memory fetches in parallel, a popcount, and an addition. But that space doubling... ew.
Poppy: A cache-optimized rank & select structure
When we taught the previous approaches to rank & select, it started dawning on us that there was some room for improvement, not from the theory side, but by applying some systems tricks. In particular, the above popcount trick, and also taking the cache hierarchy into account. We submitted our first version of the paper to ALENEX'13, and it turned out that someone beat us to popcount by a few months (oops), but the cache stuff still proved useful.
The game to play: Come up with an index that:
- Uses as little space as possible
- Performs as few cache-misses as possible to compute rank
- Doesn't use insane amounts of computation to do all of this
Our SEA 2013 paper describes a "recipe" for playing this game.
Step 1: Figure out the biggest "basic block" possible.
The basic block is the size at which you just invoke popcount in a loop. Skipping to the punchline, the answer is: One cacheline (64 bytes, or 512 bits). Larger than this, you start wasting memory bandwidth. But smaller than this and you don't gain much speed.
So a strawman structure might be:
1s_before_basic_block uint64[ bits / 512 ]
That's way better than our prior attempt: It uses only 64 bits per 512 bit block, which is 12.5% overhead. But we can do better:
Step 2: Map down to 32 bit chunks
While it's nice to support bit vectors > 232 bits, you probably don't need very many 232 bit blocks. So we move to a two-level index:
1s_before_32_bit_block uint64[ bits >> 32 ]
1s_within_32_bit_block uint32[ bits / 512 ]
And simply add the two together, plus the popcount within the 512 bit basic block:
func rank(x uint64, bv bitvector) uint64 {
return 1s_before_32_bit_block[x >> 32] +
1s_within_32_bit_block[x / 512] +
popcount_in_basic_block(x, bv)
}
That has us down to about 6.25% overhead. But we can still do a bit better by using more levels of index hierarchy, but interleaving them together so that you can fetch the entire index chunk in one cacheline miss. This brings us to the final structure for poppy:

The structure mixes an "L0" index that lets the rest of the entries only need to count 32 bits. The L0 index has one 64 bit integer for every 232 bits -- so it fits easily in CPU cache. It then stores index entries for four consecutive basic blocks using 62 bits (plus two bits of padding): The first one uses 32 bits, and it stores the next 3 by simply counting the number of bits within each block. To find out the total popcount, then, you:
- Grab a 64 bit number from the L0 index. Add it to:
- A 32 bit number from the start of the second-level index;
- Sum up the 0, 1, 2, or 3 L2 entries to get to the basic block you want.
By being willing to do a few more (cheap) addition operations, the index structure for a given x fits in a 64 bit word. Thus, calculating rank takes:
- 1 cache hit for fetching the L0 entry, in parallel with
- 1 cache miss for fetching the L1/2 index, in parallel with
- 1 cache miss to fetch the bitvector basic block of 512 bits
- Up to 8 popcount instructions that can be issued in parallel;
- 2-4 addition operations;
In the SEA paper, we also show how this structure works very nicely within a previous approach for select and simply makes it faster.
- Paying attention to the cache hierarchy can provide a big win for algorithm engineering.
- There are opportunities for systems-thinkers to contribute to the state of the art in algorithm engineering.
- This stuff is ridiculously fun to play with. :-)
We started with rank & select because they're one of the basic building blocks for higher-level succinct data structures. I'm not 100% sure where we're going to go from here in terms of the classical approaches, but now we've got a very solid, fast implementation to build upon. Using this, for example, one could represent the structure of an n-node binary tree using 1.04*2*n bits and navigate randomly within it at pretty high speed. Probably slower than in the pointer-based version, unless this one was so much smaller that it fit comfortably in cache. Which isn't entirely crazy...
Next up, someone should ask about the joys of encoding monotone integer sequences. The tricks (not ours, existing ones) are gorgeously fun.


Comments
Post a Comment